浅析 SplitChunksPlugin 及代码分割的意义
heweixiaoheweixiao -
有同事分享webpack的代码分割,其中提到了SplitChunksPlugin,对于文档上的描述大家有着不一样的理解,所以打算探究一下。
Q:什么是 SplitChunksPlugin?SplitChunksPlugin 是用来干嘛的?
A: 最初,chunks(以及内部导入的模块)是通过内部webpack 图谱中的父子关系关联的。CommonsChunkPlugin曾被用来避免他们之间的重复依赖,但是不可能再做进一步的优化。从webpack v4 开始,移除了CommonsChunkPlugin,取而代之的是 optimization.splitChunks。SplitChunksPlugin可以去重和分离 chunk
webpack的中文文档,对SplitChunksPlugin的描述是这样子的:

针对以上的第二点描述新的 chunk 体积大于 20kb(在进行 min+gz 之前的体积),有同事是这么理解的:chunk 大于 20kb 时,webpack会对当前的chunk进行拆包,一般情况下,100kb的包会拆成 5 个包 即 5 * 20kb = 100kb. 如果有并发请求的限制,webpack会自动把某些包合并,如并发请求数是 2 ,那么这个100kb的包将会被拆成 2 个,每个包的大小为50kb,即 2 * 50kb = 100kb。
而我对此表示有不同的看法:
既然这个插件是用来对代码进行分割的,那么没有必要再对代码进行合并,这样子会让这个插件变得不纯粹,而且会增加插件逻辑的复杂度,所以这句话的意思应该是分割出来的新chunk得大于 20kb。
由于大家都不是三言两语就能被说服的,所以打算去查查资料,动动手验证一下到底是怎么一回事。
文档资料一、英文文档首先为了避免中华语言博大精深,导致个人理解有偏差,我先去查看了一下英文文档,英文文档上是这么描述的:

关键词 new chunk:新的chunk,只有分离出来的才算是新的chunk吧,那么这句话的意思应该就是新的chunk将会大于20kb。
其次为了再次避免个人英文理解有偏差,到网上去翻阅了一些社区文章:

作者:前端论道
链接:https://juejin.cn/post/6844904103848443912
来源:稀土掘金
从上图中可以看到,第三方包vue已经超过了默认的20kb,直接被分割成一个单独的2.js的包,并不是按照20kb平均分成多个包。
// index.js
import "./a";
console.log("this is index");// a.js
import "vue";
import "react";
import "jquery";
import "lodash";
console.log("this is a");// webpack.config.js
const path = require('path');
module.exports = {
mode: "production",
entry: './src/index.js',
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'dist'),
},
optimization: {
splitChunks: {
chunks: 'all',
},
},
};编译结果: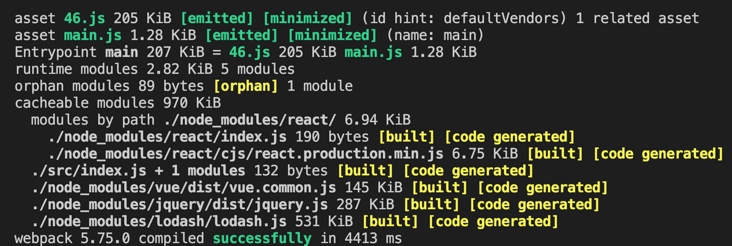
从编译的结果中可以看到,除了main.js,仅仅多出了一个205kb的46.js。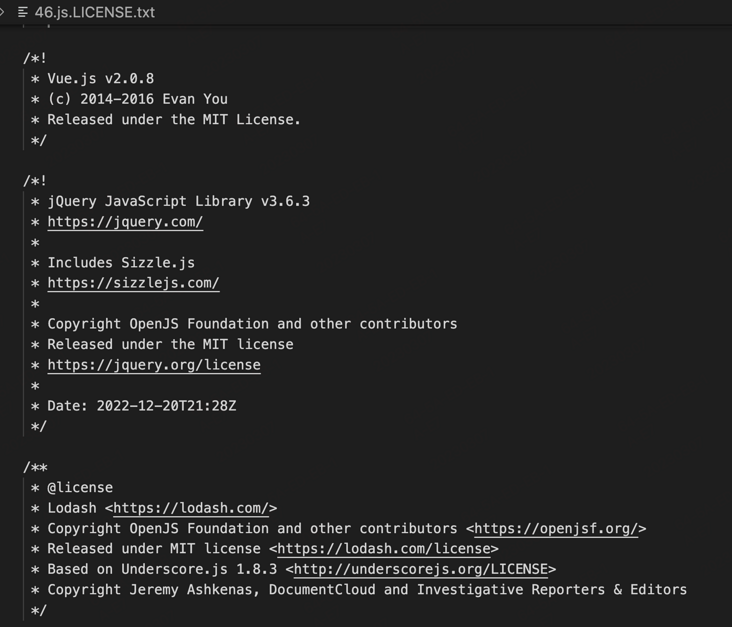
从上图可以看出,vue、jquery、lodash等一起都被打包到 46.js 中,并没有以20kb为基础平均分割成很多个chunk。
新的 chunk 体积大于 20kb(在进行 min+gz 之前的体积),指的是引入的依赖中,在进行min+gz之前的体积大于20kb,这个依赖将会被分割出来成为一个新的chunk。
到这里还没有结束,因为我还有几个疑问:
webpack为什么要进行代码分割?浏览器的并发请求一般不是4~6个吗?为什么文章里提到的按需请求和初始请求都是小于或者等于30?webpack为什么要进行代码分割?前端代码体积变大,调试和上线都需要很长的编译时间,开发时修改一行代码也要重新打包整个脚本。用户需要花额外的时间和带宽下载更大体积的脚本文件。一、按需加载
首次加载只加载必要的内容,提升用户的首次加载的速度。其他的模块可以根据用户的交互进行按需加载,即用户跳转新路由或者点击的页面的时候再进行加载。
二、有效利用缓存
通过webpack在打包是对代码进行分割,可以有效的利用缓存:打包编译的时候,只需要编译需要更新的部分;用户访问的时候只需要下载被修改的文件即可。
场景:
你有一个体积巨大的文件,并且只改了一行代码,用户仍然需要重新下载整个文件。但是如果你把它分为了两个文件,那么用户只需要下载那个被修改的文件,而浏览器则可以从缓存中加载另一个文件。
三、预获取/预加载模块
prefetch(预获取):将来某些导航下可能需要的资源:这会生成 <link rel="prefetch" href="login-modal-chunk.js"> 并追加到页面头部,指示着浏览器在闲置时间预取 login-modal-chunk.js 文件。 preload(预加载):当前导航下可能需要资源---
preload chunk 会在父 chunk加载时,以并行方式开始加载。prefetch chunk 会在父 chunk 加载结束后开始加载。---
preload chunk 具有中等优先级,并立即下载。prefetch chunk 在浏览器闲置时下载。---
preload chunk 会在父 chunk 中立即请求,用于当下时刻。prefetch chunk 会用于未来的某个时刻。--- 浏览器支持程度不同。浏览器的并发请求一般不是4~6个吗?为什么文章里提到的按需请求和初始请求都是小于或者等于30?
随着http2.0的普及,浏览器的并发请求的限制得到了很好的解决。通过http2.0的多路复用,理论上可以通过一个TCP请求发送无数个请求。然后翻了下webpack代码仓库源码,发现了以下注释:
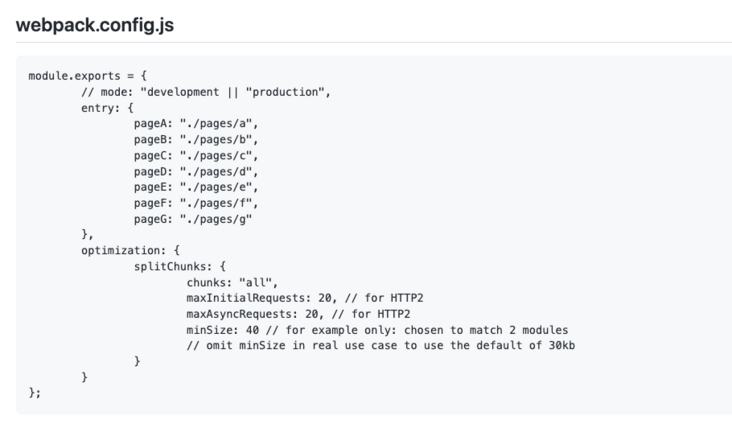
http2.0支持情况:

所以在webpack的代码分割逻辑里,按需请求和初始请求都超过了之前浏览器对http1.0单个域名请求的限制。
参考文档:
webpack中文文档
webpack英文文档
如何使用 splitChunks 精细控制代码分割
Tags 标签
javascriptwebpack前端htmlhtml5扩展阅读
HTML5离线存储
2020-03-06 14:13:06 []CSGO电竞API数据接口【West S2战队数据】分享使用演示
2020-09-03 07:18:05 []wamp配置局域网访问
2020-09-04 01:12:17 []接口测试工具apipost3.0版本对于流程测试和引用参数变量
2020-09-15 15:12:13 []vs code的使用与常用插件和技巧大全总结
2020-09-17 03:07:47 []没有伞的孩子 [必须] 要学会奔跑
2020-09-17 04:49:49 []学习之apipost3.0文档移动和文档管理教程
2020-09-18 06:19:35 []分享—如何使用apipost模拟手机实现请求发送
2020-09-18 12:15:00 []【分享】apipost如何使用mock测试
2020-09-19 21:59:25 []Apipost使用技巧之分享
2020-09-19 11:44:49 []加个好友,技术交流
