01| OCFS2文件系统磁盘布局分析
惊雷 -
文件系统本质上是把文件存入磁盘,因此,理解文件系统的磁盘整体布局对于理解一款文件系统非常的重要,文件系统的所有功能都是围绕磁盘布局和对其管理展开的,下面我们一起看一下OCFS2集群文件系统的磁盘整体布局。
一、格式化format:
mkfs.ocfs2 -b 4K -C 1M -N 32 -J size=128M -L "xxx" -T vmstore --fs-features=indexed-dirs,refcount --cluster-stack=o2cb --cluster-name=ocfs2 fs.img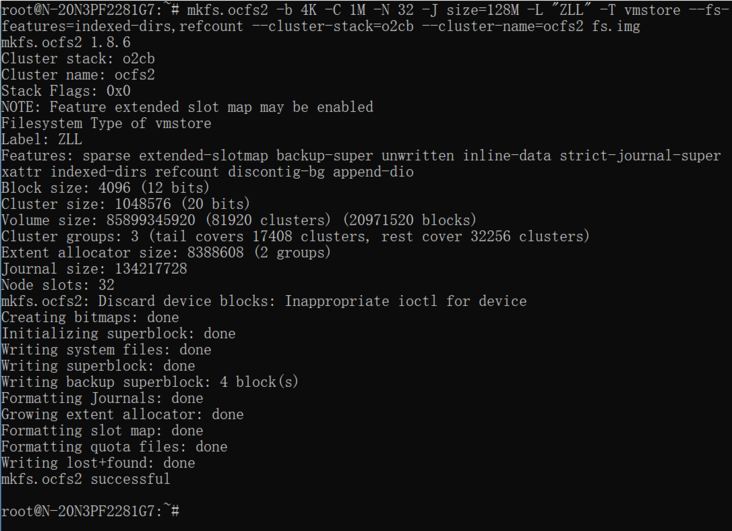
格式化参数解释:
-b, --block-size block-size 文件系统执行IO的最小单元,本例取 block 4KB=4096=2^10-C, --cluster-size cluster-size 为文件数据分配空间的最小单元,本例取 cluster 1MB=2^20
-N, --node-slots number-of-node-slots 节点槽位,指向一系列的系统文件,每个槽位被一个节点唯一使用。槽位的个数表示该volume可同时被多少个节点mount。
-J, --journal-options options OCFS2采用预写日志WAL(Write-Ahead Log),使用了JBD2,用户可配置,根据文件系统类型和卷大小决定,默认值:datafiles类型64MB,vmstore类型128MB,mail类型256MB
-L, --label volume-label 对卷做标签,为了方便管理。
-T filesystem-type Valid types are mail, datafiles and vmstore.
mail:用作邮件服务器存储,将大量的元数据变为大量的小文件,使用大一点的日志journal比较有益。
datafiles:建议较少地全部分配大文件,要求较少的元数据改变,因此,使用大一点的日志journal无益。
vmstore:正如名字所示,被稀疏分配大文件的虚拟机镜像
--fs-features=[no]sparse... 指定使能或禁用某些特性,比如:稀疏文件、非写入范围、备份超级块
--fs-feature-level=feature-level Valid values are max-compat, default and max-features. 默认支持稀疏文件、非写入范围、内联数据。
查看根目录和系统目录
通过debugfs.ocfs2,可以看到系统文件,本例格式化指定 -N 32,因此,一些带slot号的系统文件,如:local_allock:0000~0031,如下截图仅显示部分,其余已将其省略,不影响分析。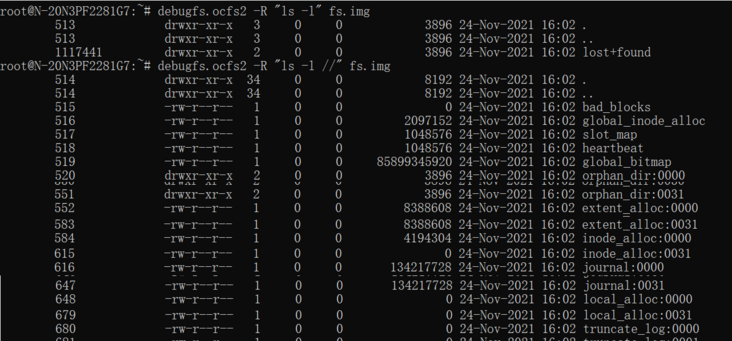
通过格式化的参数,可以得到如下基础数据信息,这些信息可以方便的进行计算。
1 block 4KB = 4096 = 2^10
1 cluster 1MB = 2^20
1 cluster = 256 blocks = 2^8二、SuperBlock
对于一个文件系统而言SuperBlock是最重要的,它描述了一个文件系统的基本数据信息,含有许多重要的关键信息,文件系统被mount操作后,首先要读取SuperBlock。格式化后,可以看到SuperBlock的信息如下:
其中,有一个关键的数据参数来自格式化命令行,如:Block Size Bits: 12、Cluster Size Bits: 20等,而SuperBlock Blkno是要提前规定好的,后面的一些关键信息都是由此SuperBlock Blkno计算而来,比如:First Cluster Group Blknum: 256,进而计算出Root Blknum: 513、System Dir Blknum: 514。> #define OCFS2_SUPER_BLOCK_BLKNO 2
SuperBlock在磁盘上的数据结构如下: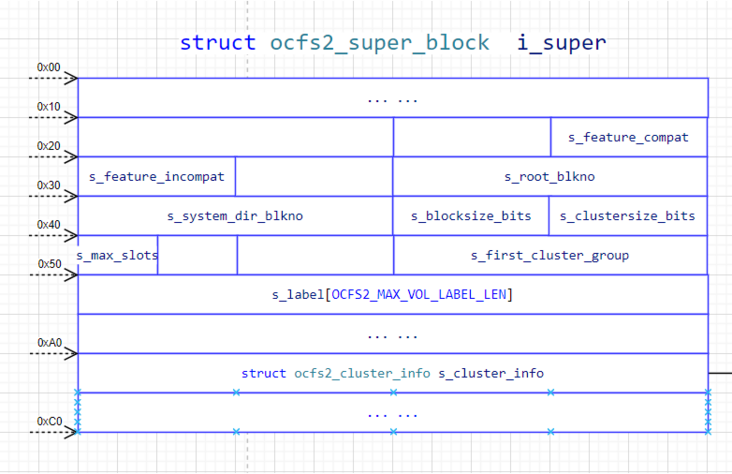
格式化最重要的就是规定好磁盘如何划分和布局,因此,需要先划分簇组Cluster Groups。
三、下面分析OCFS2磁盘的整体布局:
OCFS2磁盘的整体布局主要描述如何实现对整个磁盘的管理,OCFS2将磁盘划分为若干个Cluster Group进行管理,称为簇组(Cluster Group),在Ext4文件系统中叫块组(Block Group),用途都是一样的。如下图所示: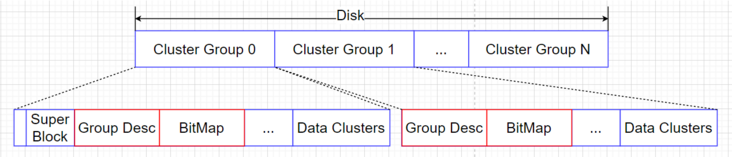
每个Cluster Group都由若干个clusters组成,包含对Cluster Group的描述信息Descriptor+BitMap、Data Clusters。第一个Cluster Group比较特殊,因为它含有OCFS2的元数据信息,包含SuperBlock、系统文件夹和系统文件。
Cluster Group内磁盘空间的管理由一个描述簇组信息的Block来体现,由该Block剩余空间用位图BitMap来管理整个簇组Cluster Group。位图BitMap中的每一位Bit与该Cluster Group中的一个cluster对应,如果第i个cluster对应的Bit位在BitMap中为1,表示该cluster已经被分配出去,0则表示没有被使用,OCFS2通过位图BitMap来确认哪些clusters可以使用(本例中1cluster=1MB)。
系统文件global_bitmap
用来描述Cluster Groups信息的系统文件是global_bitmap(global_bitmap 全局位图,用于实现对cluster group的全局管理,访问时需要通过分布式锁进行保护。)系统文件的磁盘数据结构是struct ocfs2_dinode,如下图所示: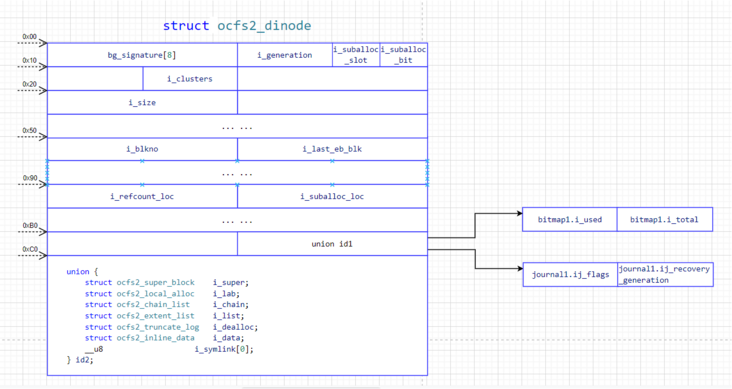
其中用来描述Cluster Group信息的是struct ocfs2_dinode.id2.ocfs2_chain_list.ocfs2_chain_rec,如下图所示: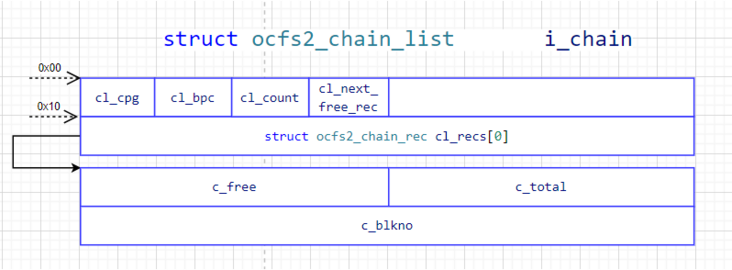
其中chain_list就是Cluster Groups List,该磁盘数据结构记录了整个磁盘分为几个Cluster Groups。每个Cluster Group Chain用ocfs2_chain_rec来描述,ocfs2_chain_rec.c_blkno就是描述每个Cluster Group的Block块位图(BitMap),磁盘数据结构是struct ocfs2_group_desc,用1个Block来表示,如下所示:
从0x00~0x40 = 64B,1Block 4096B - 64B = 余4032 B * 8 bits = 32256 bits,因此,一个ocfs2_group_desc可表示32256个clusters,所以每个cluster group里面cluster数目,即:1个cluster group含32256 clusters = 32256MB = 31.5GB。一块磁盘Disk或卷Volume可用cluster groups的总数 = 总clusters / 每个cluster group含cluster数目,最后一个cluster group里包含剩余的cluster数目。本例中,80G Volume = 81920 clusters,(81920 clusters + 32256 clusters - 1)/ 32256 clusters = 3 cluster groups。
下图中显示了在本例中全局位图global_bitmap记录的Cluster Groups信息:一共有3个cluster group,Group Chain: 0、1、2
图中的blkno 256 / blkno 8257536 / blkno 16515072,每个blkno都是一个struct ocfs2_group_desc,用来表述本cluster group的bitmap信息。
簇组描述符:ocfs2_group_desc
格式化信息中也显示First Cluster Group Blknum: 256,那么blkno 256是怎么来的呢?blkno 8257536、blkno 16515072又是怎么来的?接下来一步一步分析。
首先,格式化首先确定global_bitmap的结构,重点是分cluster group和确定每个cluster group的descriptor block。
根据superblock blkno 2 计算出first_cluster_group_blkno = blkno 256,而剩下的cluster group N都是每个cluster group的第一个block。而first cluster group不是第一个block是因为blkno 0, 1被预留了,用来表示ocfs version2,而blkno 2用来表示SuperBlock,所以选择了global_bitmap chain 0中下标是1的cluster的第1个block 256。
如下截取关键代码所示:
s->global_bm = initialize_bitmap (s, s->volume_size_in_clusters,//初始化全局global_bitmap
s->cluster_size_bits,//20 bits
"global bitmap", tmprec);
/* to the next aligned cluster */
s->first_cluster_group = (OCFS2_SUPER_BLOCK_BLKNO + 1);//Block 3
s->first_cluster_group += ((1 << c_to_b_bits) - 1); //1<<8 = 256 - 1 = 255 +3 = 258
s->first_cluster_group >>= c_to_b_bits;//258>>8 = 1
s->first_cluster_group_blkno = (uint64_t)s->first_cluster_group << c_to_b_bits;// 1<<8 = Block 256
chain = 1;
blkno = (uint64_t) s->global_cpg << (s->cluster_size_bits - s->blocksize_bits);//确定chain 1 的group descriptor blkno 32256 << 8 = blkno 8257536
cpg = s->global_cpg;
blkno += (uint64_t) s->global_cpg << (s->cluster_size_bits - s->blocksize_bits);//确定下一个chain的group descriptor blkno 16515072 = blkno 8257536 + 32256 << 8 = blkno 8257536 * 2
chain++;//以此类推由于Cluster Group 0 比较特殊,因为这里记录了SuperBlock和系统文件,那么此时,需要指出的是在Cluster Group 0 的位图global_bitmap中,哪些bits被占用了呢?前面已分析这里的1bit = 1cluster = 1MB = 256 blocks。SupberBlock blkno 2在global_bitmap的第0位cluster中,所以global_bitmap第0位被置为1,First Cluster Group Blkno 256在global_bitmap的第1位cluster中,所以global_bitmap第1位被置为1。
系统文件inode
接下来分析根目录root_dir(513)、系统目录system_dir(514)、各个系统文件的inode号是如何分配的。
首先确定系统文件从哪里开始申请inode,首先要做的一件事就是初始化global_inode_alloc系统文件,如下图所示:.png")
先从global_bitmap中申请总的系统文件所用的Blocks总数目,本例需要203个,通过如下代码算得需要2bits,
num_bits = (bytes + bitmap->unit - 1) >> bitmap->unit_bits;//(need bytes + 1MB - 1) >> 20 = need cluster bits: (831488+1,048,576-1)/1,048,576 约=1.79 = 2bits所以从global_bitmap中申请2个可用bit位,group chain 0中bits可满足,又由于第0,1个bit的cluster已经被superblock 2和group descriptor blkno 256所在的cluster位设置了,所以获得的是第2,3个bit位cluster,即:2MB位置处开始,这就是blkno 512。如下截取的部分关键代码:
/*
* Now allocate the global inode alloc group
*/
tmprec = &(record[GLOBAL_INODE_ALLOC_SYSTEM_INODE][0]);
need = blocks_needed(s);//计算目录和系统目录及系统文件总共需要的Block数目:203
alloc_bytes_from_bitmap(s, need << s->blocksize_bits, //从global_bitmap中申请这些Block数目<<12 = need bytes
s->global_bm, //现在global_bitmap的group0的0,1/group1的0/group2的0位被占
&(crap_rec.extent_off), //出参:从偏移offset 2MB处,即:blkno 512
&(crap_rec.extent_len)); //出参:长度2MB大小可用于系统inode
s->system_group =initialize_alloc_group(s, "system inode group", tmprec,
crap_rec.extent_off >> s->blocksize_bits, //偏移offset 2MB处,即:blkno 512
0,crap_rec.extent_len >> s->cluster_size_bits, //2MB >> 20 = 2, 1 cluster = 256 bits, 2 clusters = 512bits
s->cluster_size / s->blocksize); //256, system_group里面 1 bit = 1 block接下来用这2cluster=512bits,为系统文件inode生成一个子分配器global_inode_alloc,用来为系统文件分配inode,该磁盘数据结构也复用了ocfs2_group_chain_list,仍然是用到了位图bitmap,这个位图bitmap是由blkno 512来描述的,每个group chain包含2 clusters,256bits表示一个cluster,所以1bit表示一个block大小。blkno 512是第0位bit,随后申请到的系统文件inode都是以blkno 512位基准偏移,比如:根目录(root_dir)申请到第1位bit的系统文件就是blkno 512 +1 = blkno 513,Sub Alloc Bit: 1。
申请到第i位bit的系统文件就是:blkno 512 +i = blkno (512+i),Sub Alloc Bit: i,i > 0
如下截取的部分关键代码为根目录和剩余每个系统文件申请inode:
static uint64_t
alloc_inode(State s, uint16_t suballoc_bit)
{
uint64_t ret;
uint16_t num;
alloc_from_group(s, 1, s->system_group, &ret, &num);//从system_group里面申请1 bit, blkno 512开始,共256 bits,第0位bit已经被gb_blkno512 占了,所以这里申请到第1位bit,即:blkno 513.
*suballoc_bit = (int)(ret - s->system_group->gd->bg_blkno);//blkno 513 - blkno 512 = 1 suballoc_bit
/* Did I mention I hate this code? */
return (ret << s->blocksize_bits);//返回blkno 513的字节处}
root_dir_rec.fe_off = alloc_inode(s, &root_dir_rec.suballoc_bit);
root_dir->record = &root_dir_rec;
add_entry_to_directory(s, root_dir, ".", root_dir_rec.fe_off, OCFS2_FT_DIR);//所以根目录inode blkno 513
add_entry_to_directory(s, root_dir, "..", root_dir_rec.fe_off, OCFS2_FT_DIR);
for (i = 0; i < NUM_SYSTEM_INODES; i++) {//为每个系统文件申请inode
if (hb_dev_skip(s, i))
continue;
if (feature_skip(s, i))
continue;
num = (system_files[i].global) ? 1 : s->initial_slots;
for (j = 0; j < num; j++) {
record[i][j].fe_off = alloc_inode(s, &(record[i][j].suballoc_bit));//为每个带槽位号的系统文件申请inode
sprintf(fname, system_files[i].name, j);
add_entry_to_directory(s, system_dir, fname,
record[i][j].fe_off,
S_ISDIR(system_files[i].mode) ? OCFS2_FT_DIR : OCFS2_FT_REG_FILE);
}
}如下图所示是根目录root_dir的inode信息: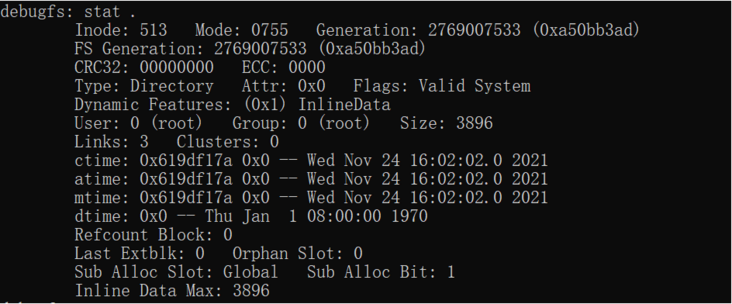
其中可以看到内联数据:Inline Data。
Inline模式:
如下图所示。即:1个block除了inode描述信息外剩下的空间,由struct ocfs2_dinode可知,0xC0之后就是inline data,所以 inline data = 1block(4096 B) - 0xC0(192 B) - 0x08(8 B)= 3896 B。当数据小于3896 B时,数据会存在inode的Inline Data中;当数据大于3896 B时,则会通过extent的方式存储。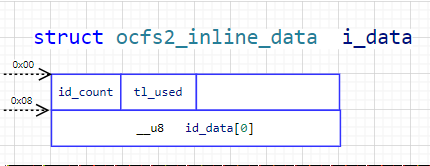
extent模式:
当inode存储的数据大于内联空间3896 B时,就会使用extent模式来存储数据。很多文件是采用了extent模式存储数据。extent模式采用B+树的方式存储数据,B+树是经典的存储数据的方式,Mysql的存储引擎InnoDB也是用的B+树存储数据。
在struct ocfs2_dinode磁盘数据结构0xC0之后有struct ocfs2_extent_list和ocfs2_extent_rec,这两个磁盘数据结构共同描述了该inode下面数据在extent模式下的分布情况。如下所示的extent磁盘数据结构: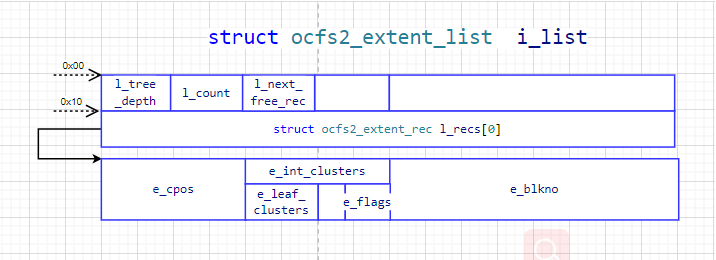
其中,l_tree_depth表示树深,该值为0,表示该树节点是叶子节点,即:e_blkno这个block块是用来存储数据的;如果该值非0,表示该节点是非叶子节点,不是用来存储数据的,而是用来记录下一个存储位置的。l_count表示extent records的数目,下图所示count: 243 = ( 1block(4096 B) - 0xC0(192 B) - 0x10(16 B) ) / (16 B)= 3888 B / 16 B = 243。
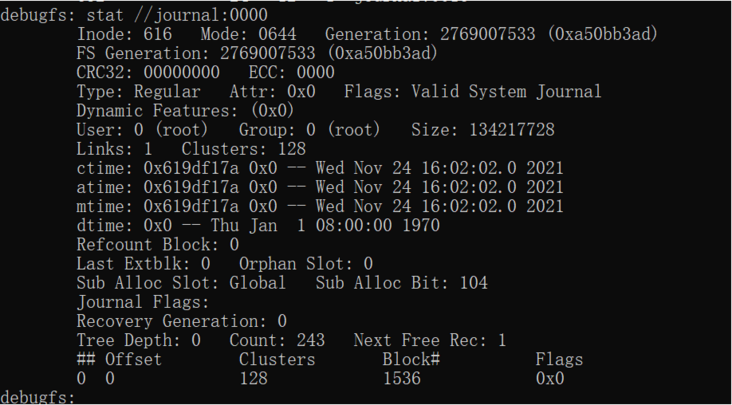
如下图所示的两个系统文件heartbeat心跳文件、日志journal:0000文件都只占了一个extent record,心跳系统文件heartbeat的extent record显示:数据存储从block 1280开始,占了1 cluster(1MB)的大小。因为数据只占了1cluster,所以在文件中的偏移(以clusters计)offset = 0。日志journal:0000系统文件从block 1536开始占了连续的128 clusters,该extent record在文件中的偏移也是offset=0。如果文件分配的extent空间是不连续的,则会出现多个extent records记录,每一个extent片段信息(offset/clusters/blkno)都会显示在extent records中,它们共同构成该文件的数据内容。
总结
综上所述,本例中格式化之后的磁盘布局如下图所示: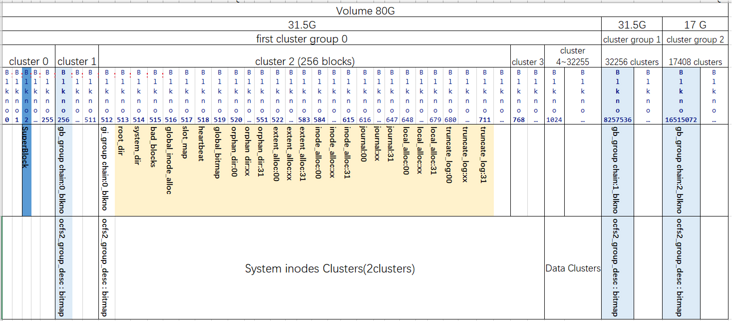
Tags 标签
clinux文件系统存储技术扩展阅读
Linux 常用命令
2019-01-12 11:26:35 []linux命令行查看系统有哪些用户
2020-06-28 19:09:43 []【问题合集】Problem with the SSL CA cert (path? access rights?)
2020-09-20 09:57:21 []关于 MAC 配置 Apache2 + PHP
2020-09-21 12:36:34 []Laravel项目上线注意点
2020-10-20 21:55:08 []PHP-FPM中-D命令的实现
2020-10-23 13:54:26 []2020年10月php面试笔记
2020-10-23 01:09:55 []协程 shell_exec 如何捕获标准错误流
2020-11-03 10:11:33 []PHP-FPM源码分析
2020-11-06 00:01:04 []加个好友,技术交流
