记某核心MongoDB集群索引优化实践
MongoDB中文社区 -
腾讯云数据库MongoDB天然支持高可用、分布式、高性能、高压缩、schema free、完善的客户端访问均衡策略等功能。云上某重点用户基于MongoDB这些优势,选用MongoDB作为主存储服务,该用户业务场景如下:
· 存储电商业务核心数据
· 查询条件多变、查询不固定,查询较复杂,查询组合众多
· 对性能要求较高
· 对存储成本有要求
· 流量占比:insert较少、update较多、find较多、峰值流量较高
· 高峰期读写流量数千/秒
通过和业务沟通,了解业务使用场景和业务述求后,通过一系列的索引优化,最终完美解决读写性能瓶颈问题。本文重点分析该核心业务索引优化过程,通过本文可以学习到以下知识点:
· 如何确定无用索引?
· 如何确定重复索引?
· 如何创建最优索引?
· 对索引的一些错误认识?
· 索引优化收益(节省90%以上CPU资源、85%磁盘IO资源、20%存储成本)
问题分析过程收到用户集群性能瓶颈反馈后,通过集群监控信息及服务器监控信息可以看出集群存在如下现象:
· Mongod节点CPU消耗过高,CPU时不时消耗接近90%,甚至100%
· 磁盘IO消耗过高,单节点IO资源消耗占整服务器60%
· 大量慢日志(主要集中在find和update),高峰期每秒数千条慢日志
· 慢日志类型各不相同,查询条件众多
· 所有慢查询都有匹配到索引
登录服务器对应节点后台,获取慢日志信息,发现mongod.log中包含大量不同类型find和update的慢日志,慢日志都有走索引,任意提取一条慢日志其内容如下:
Mon Aug 2 10:34:24.928 I COMMAND [conn10480929] command xxx.xxx command: find { find: "xxx", filter: { $and: [ { alxxxId: "xxx" }, { state: 0 }, { itemTagList: { $in: [ xx ] } }, { persxxal: 0 } ] }, limit: 3, maxTimeMS: 10000 } planSummary: IXSCAN { alxxxId: 1.0, itemTagList: 1.0 } keysExamined:1650 docsExamined:1650 hasSortStage:0 cursorExhausted:1 keyUpdates:0 writeConflicts:0 numYields:15 nreturned:3 reslen:8129 locks:{ Global: { acquireCount: { r: 32 } }, Database: { acquireCount: { r: 16 } }, Collection: { acquireCount: { r: 16 } } } protocol:op_command 227ms
Mon Aug 2 10:34:22.965 I COMMAND [conn10301893] command xx.txxx command: find { find: "txxitem", filter: { $and: [ { itxxxId: "xxxx" }, { state: 0 }, { itemTagList: { $in: [ xxx ] } }, { persxxal: 0 } ] }, limit: 3, maxTimeMS: 10000 } planSummary: IXSCAN { alxxxId: 1.0, itemTagList: 1.0 } keysExamined:1498 docsExamined:1498 hasSortStage:0 cursorExhausted:1 keyUpdates:0 writeConflicts:0 numYields:12 nreturned:3 reslen:8039 locks:{ Global: { acquireCount: { r: 26 } }, Database: { acquireCount: { r: 13 } }, Collection: { acquireCount: { r: 13 } } } protocol:op_command 158ms 从上面的日志打印可以看出,查询都有走 { alxxxId: 1.0, itemTagList: 1.0 } 索引,走该索引扫描的keysExamined为1498行,扫描的docsExamined为1498行,但是返回的doc文档数却只有nreturned=3行。
通过上面的日志核心信息可以看出,满足条件的数据只有3条,但是却扫描了1498行数据和索引,说明查询有走索引,但是不是最优所有。
获取用户SQL查询模型及已有索引信息上面的分析可以确定问题出现在索引不是最优,大量查询找了很多无用数据。
3.1. 和用户接触,了解用户SQL模型
通过和用户沟通,收集到用户查询、更新主要涉及以下SQL类型:
· 常用查询、更新类SQL
基于AlxxxId(用户ID)+itxxxId(单个或多个)
基于AlxxxId查询count
基于AlxxxId通过时间范围(createTime)进行分页查询,部分查询会拼接state及其他字段
基于AlxxxId,ParentAlxxxId,parentItxxxId,state组合查询
基于ItxxxId(单个或多个)查询数据
基于AlxxxId, state, updateTime组合查询
基于AlxxxId, state,createTime, totalStock(库存数量)组合查询
基于AlxxxId(用户ID)+itxxxId(单个或多个)+任意其他字段组合
基于AlxxxId, digitalxxxrmarkId(水印ID), state进行查询
基于AlxxxId, itemTagList(标签ID),state等进行查询
基于AlxxxId+itxxxId(单个或多个) +其他任意字段进行查询
其他查询
· 统计类count查询SQL
AlxxxId,state, persxxal 组合
AlxxxId, state,itemType 组合
AlxxxId(用户ID)+itxxxId(单个或多个)+任意其他字段组合
3.2. 获取集群已有索引
通过db.xxx.getindex({})获取到该表的索引信息如下,总计30个索引:
{ "alxxxId" : 1, "state" : -1, "updateTime" : -1, "itxxxId" : -1, "persxxal" : 1, "srcItxxxId" : -1 }
{ "alxxxId" : 1, "image" : 1 }
{ "itexxxList.vidxxCheck" : 1, "itemType" : 1, "state" : 1 }
{ "alxxxId" : 1, "state" : -1, "newsendTime" : -1, "itxxxId" : 1, "persxxal" : 1 }
{ "_id" : 1 }
{ "alxxxId" : 1, "createTime" : -1, "checkStatus" : 1 }
{ "alxxxId" : 1, "parentItxxxId" : -1, "state" : -1, "updateTime" : -1, "persxxal" : 1, "srcItxxxId" : -1 }
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "updateTime" : -1, "persxxal" : -1 }
{ "srcItxxxId" : 1 }
{ "createTime" : 1 }
{ "itexxxList.boyunState" : -1, "itexxxList.wozhituUploadServerId": -1, "itexxxList.photoQiniuUrl" : 1, "itexxxList.sourceType" : 1 }
{ "alxxxId" : 1, "state" : 1, "digitalxxxrmarkId" : 1, "updateTime" : -1 }
{ "itxxxId" : -1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "videoCover" : 1 }
{ "alxxxId" : 1, "itemType" : 1 }
{ "alxxxId" : 1, "state" : -1, "itemType" : 1, "persxxal" : 1, "updateTime" : 1 }
{ "alxxxId" : 1, "itxxxId" : 1 }
{ "itxxxId" : 1, "alxxxId" : 1 }
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "itemTagList" : 1 }
{ "itexxxList.photoQiniuUrl" : 1, "itexxxList.boyunState" : -1, "itexxxList.sourceType" : 1, "itexxxList.wozhituUploadServerId" : -1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "updateTime" : 1 }
{ "updateTime" : 1 }
{ "itemPhoxxIdList" : -1 }
{ "alxxxId" : 1, "state" : -1, "isTop" : 1 }
{ "alxxxId" : 1, "state" : 1, "itemResxxxIdList" : 1, "updateTime" : -1 }
{ "alxxxId" : 1, "state" : -1, "itexxxList.photoQiniuUrl" : 1 }
{ "itexxxList.qiniuStatus" : 1, "itexxxList.photoNetUrl" : 1, "itexxxList.photoQiniuUrl" : 1 }
{ "itemResxxxIdList" : 1 }从上一节可以看出,该集群查询复杂,同时索引众多,通过分析已有索引和用户数据模型,对已有索引做如下优化,最终有效索引减少到8个。
4.1. 第一轮优化:删除无用索引
MongoDB默认提供有索引统计命令来获取各个索引命中的次数,该命令如下:
> db.xxxxx.aggregate({"$indexStats":{}})
{ "name" : "alxxxId_1_parentItxxxId_1_parentAlxxxId_1", "key" : { "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1 },"host" : "TENCENT64.site:7014", "accesses" : { "ops" : NumberLong(11236765),"since" : ISODate("2020-08-17T06:39:43.840Z") } }该聚合输出中的几个核心指标信息如下表:
字段内容
说明
name
索引名,代表是针对那个索引的统计。
ops
索引命中次数,也就是所有查询中采用本索引作为查询索引的次数。
上表中的ops代表命中次数,如果命中次数为0或者很小,说明该索引很少被选为最优索引使用,因此可以任务是无用索引,可以直接删除。
获取用户核心表索引统计信息,如下:
db.xxx.aggregate({"$indexStats":{}})
{ "alxxxId" : 1, "state" : -1, "updateTime" : -1, "itxxxId" : -1, "persxxal" : 1, "srcItxxxId" : -1 } "ops" : NumberLong(88518502)
{ "alxxxId" : 1, "image" : 1 } "ops" : NumberLong(293104)
{ "itexxxList.vidxxCheck" : 1, "itemType" : 1, "state" : 1 } "ops" : NumberLong(0)
{ "alxxxId" : 1, "state" : -1, "newsendTime" : -1, "itxxxId" : -1, "persxxal" : 1 } "ops" : NumberLong(33361216)
{ "_id" : 1 } "ops" : NumberLong(3987)
{ "alxxxId" : 1, "createTime" : 1, "checkStatus" : 1 } "ops" : NumberLong(20042796)
{ "alxxxId" : 1, "parentItxxxId" : -1, "state" : -1, "updateTime" : -1, "persxxal" : 1, "srcItxxxId" : -1 } "ops" : NumberLong(43042796)
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "updateTime" : -1, "persxxal" : -1 } "ops" : NumberLong(3042796)
{ "itxxxId" : -1 } "ops" : NumberLong(38854593)
{ "srcItxxxId" : -1 } "ops" : NumberLong(0)
{ "createTime" : 1 } "ops" : NumberLong(62)
{ "itexxxList.boyunState" : -1, "itexxxList.wozhituUploadServerId" : -1, "itexxxList.photoQiniuUrl" : 1, "itexxxList.sourceType" : 1 } "ops" : NumberLong(0)
{ "alxxxId" : 1, "state" : 1, "digitalxxxrmarkId" : 1, "updateTime" : -1 } "ops" : NumberLong(140238342)
{ "itxxxId" : -1 } "ops" : NumberLong(38854593)
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 } "ops" : NumberLong(132237254)
{ "alxxxId" : 1, "videoCover" : 1 } { "ops" : NumberLong(2921857)
{ "alxxxId" : 1, "itemType" : 1 } { "ops" : NumberLong(457)
{ "alxxxId" : 1, "state" : -1, "itemType" : 1, "persxxal" : 1, " itxxxId " : 1 } "ops" : NumberLong(68730734)
{ "alxxxId" : 1, "itxxxId" : 1 } "ops" : NumberLong(232360252)
{ "itxxxId" : 1, "alxxxId" : 1 } "ops" : NumberLong(145640252)
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 } "ops" : NumberLong(689891)
{ "alxxxId" : 1, "itemTagList" : 1 } "ops" : NumberLong(2898693682)
{ "itexxxList.photoQiniuUrl" : 1, "itexxxList.boyunState" : 1, "itexxxList.sourceType" : 1, "itexxxList.wozhituUploadServerId" : 1 } "ops" : NumberLong(511303207)
{ "alxxxId" : 1, "parentItxxxId" : 1, "state" : 1 } "ops" : NumberLong(0)
{ "alxxxId" : 1, "parentItxxxId" : 1, "updateTime" : 1 } "ops" : NumberLong(0)
{ "updateTime" : 1 } "ops" : NumberLong(1397)
{ "itemPhoxxIdList" : -1 } "ops" : NumberLong(0)
{ "alxxxId" : 1, "state" : -1, "isTop" : 1 } "ops" : NumberLong(213305)
{ "alxxxId" : 1, "state" : 1, "itemResxxxIdList" : 1, "updateTime" : 1 } "ops" : NumberLong(2591780)
{ "alxxxId" : 1, "state" : 1, "itexxxList.photoQiniuUrl" : 1} "ops" : NumberLong(23505)
{ "itexxxList.qiniuStatus" : 1, "itexxxList.photoNetUrl" : 1, "itexxxList.photoQiniuUrl" : 1 } "ops" : NumberLong(0)
{ "itemResxxxIdList" : 1 } "ops" : NumberLong(7)
该业务已经运行一段时间,首先把ops小于10000的索引删除,满足该条件的索引如上面的红色部分索引。
通过该轮删除11个无用索引后,剩余有用索引30-11=19个索引。
4.2. 第二轮优化:删除重复索引
重复索引主要包括以下几类:
· 查询顺序引起的索引重复
例如该业务不同开发写了如下两种查询:
db.xxxx.find({{ "alxxxId" : xxx, "itxxxId" : xxx }})
db.xxxx.find({{ " itxxxId " : xxx, " alxxxId " : xxx }})为了应对这两种查询SQL,DBA创建了两个索引:
{ alxxxId :1, itxxxId:1 }和{ itxxxId :1, alxxxId:1}这两个SQL实际上创建任何一个索引即可,无需两个索引,因此这就是无用索引。
· 最左原则匹配引起的索引重复
例如下面的三个索引存在重复索引:
{ itxxxId:1, alxxxId:1 }和{ itxxxId :1}这两个索引,{ itxxxId :1}即为重复索引。
· 包含关系引起的索引重复
例如上面的以下两个索引为重复索引:
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, " state " : 1 }和用户确认,用户创建这三个索引,是因为有如下三个查询:
Db.xxx.find({ "alxxxId" : xxx, "parentItxxxId" : xx, "parentAlxxxId" : xxx, "state" : xxx })
Db.xxx.find({ "alxxxId" : xxx, " parentAlxxxId " : xx, " state " : xxx })
Db.xxx.find({ "alxxxId" : xxx, " state " : xxx })这几个查询都包含公共字段,因此可以合并为一个索引来满足这两类SQL的查询,合并后的索引如下:
{ "alxxxId" : 1, " state " : 1, " parentAlxxxId " : 1, parentItxxxId :1}通过以上几个索引原则优化后,以下几个索引可以优化,优化前索引:
{ itxxxId:1, alxxxId:1 }
{ alxxxId:1, itxxxId:1 }
{itxxxId:1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, " state " : 1 }这6个索引可以合并优化为如下2个索引:
{ itxxxId:1, alxxxId:1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }4.3. 第三轮优化:获取数据模型,剔除唯一索引引起的无用索引
通过分析表中数据各个字段模块组合,发现alxxxId和itxxxId字段为高频字段,通过分析字段schema信息,随机抽取一部分数据,发现这两个字段组合是唯一的。于是和用户确认,用户反馈这两个字段的任意组合都代表一条唯一的数据。
如果{alxxxId:1, itxxxId:1}索引可以确定唯一性,则这两个字段和任何字段的组合都是唯一的。因此下面的几个索引可以合并为一个索引:
{ "alxxxId" : 1, "state" : -1, "updateTime" : -1, "itxxxId" : 1, "persxxal" : 1, "srcItxxxId" : -1 }
{ "alxxxId" : 1, "state" : -1, "itemType" : 1, "persxxal" : 1, " itxxxId " : 1 }
{ "alxxxId" : 1, "state" : -1, "newsendTime" : -1, "itxxxId" : 1, "persxxal" : 1 }
{ "alxxxId" : 1, "state" : 1, "itxxxId" : 1, "updateTime" : -1 }
{ itxxxId:1, alxxxId:1 }上面的5个索引可以去重合并为以下一个索引:{ itxxxId:1, alxxxId:1 }
4.4. 第四轮优化:非等值查询引起的无用重复索引优化
从前面的30个索引可以看出,索引中有部分为时间类型字段,如createTime、updateTime,这类字段一般用于范围查询,通过和用户确认,这些字段确实用于各种范围查询。由于范围查询属于非等值查询,如果范围查询字段出现在索引字段前面,则后面字段无法走索引,例如如下查询及索引:
db.collection.find({{ "alxxxId" : xx, "parentItxxxId" : xx, "state" : xx, "updateTime" : {$gt: xxxxx}, "persxxal" : xxx, "srcItxxxId" : xxx } })
db.collection.find({{ "alxxxId" : xx, "state" : xx, "parentItxxxId" : xx, "updateTime" : {$lt: xxxxx}, "persxxal" : xxx} })用户为这两个查询增加了以下两个索引:
第一个索引如下:
{ "alxxxId" : 1, "parentItxxxId" : -1, "state" : -1, "updateTime" : -1, "persxxal" : 1, "srcItxxxId" : -1 }
第二个索引如下:
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "updateTime" : -1, "persxxal" : -1 }由于这两个查询都包含updateTime字段,并进行范围查询。由于除了updateTime字段以外的字段都是等值查询,因此上面两个查询实际上updateTime右边的字段无法走索引。也就是上面的第一个索引persxxal和srcItxxxId字段无法匹配索引,第二个索引persxxal字段无法匹配索引。
同时由于这两个索引字段基本相同,为了更好保证更多字段走索引,因此可以合并优化为如下一个索引,确保更多字段能够走索引:
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "persxxal" : -1, "updateTime" : -1 }4.5. 第五轮优化:去除查询频率较低的字段对应索引
第一轮优化删除无用索引的时候,过滤掉了命中率低于10000次以下的索引。但是,还有一部分索引相比高频命中次数(数十亿次)命中次数也相对较低(命中次数只有几十万),这部分较低频命中次数的索引如下:
{ "alxxxId" : 1, "image" : 1 } "ops" : NumberLong(293104)
{ "alxxxId" : 1, "videoCover" : 1 } "ops" : NumberLong(292857) 调低慢日志时延阈值,分析这两个查询对应日志,如下:
Mon Aug 2 10:56:46.533 I COMMAND [conn5491176] command xxxx.tbxxxxx command: count { count: "xxxxx", query: { alxxxId: "xxxxxx", itxxxId: "xxxxx", image: "http:/xxxxxxxxxxx/xxxxx.jpg" }, limit: 1 } planSummary: IXSCAN { itxxxId: 1.0,alxxxId:1.0 } keyUpdates:0 writeConflicts:0 numYields:1 reslen:62 locks:{ Global: { acquireCount: { r: 4 } }, Database: { acquireCount: { r: 2 } }, Collection: { acquireCount: { r: 2 } } } protocol:op_query 4ms
Mon Aug 2 10:47:53.262 I COMMAND [conn10428265] command xxxx.tbxxxxx command: find { find: "xxxxx", filter: { $and: [ { alxxxId: "xxxxxxx" }, { state: 0 }, { itemTagList: { $size: 0 } } ] }, limit: 1, singleBatch: true } planSummary: IXSCAN { alxxxId: 1, videoCover: 1 } keysExamined:128 docsExamined:128 cursorExhausted:1 keyUpdates:0 writeConflicts:0 numYields:22 nreturned:0 reslen:108 locks:{ Global:{ acquireCount: { r: 46 } }, Database: { acquireCount: { r: 23 } }, Collection: { acquireCount: { r: 23 } } } protocol:op_command 148ms 分析日志发现用户请求中的image都是和alxxxId,itxxxId进行组合查询,前面提到alxxxId,itxxxId是唯一的,从查询计划也可以看出,image字段完全没有走索引。因此{ "alxxxId" : 1, "ixxxge" : 1 }索引可以删除。
同理,分析日志发现用户查询条件中没有携带videoCover,只是部分查询走了{ alxxxId: 1, videoCover: 1 } 索引,并且keysExamined、docsExamined与nreturned不相同,所以可以确认实际只匹配了alxxxId索引字段。因此,该索引{ alxxxId: 1, videoCover: 1 } 可以删除。
4.6. 第六轮优化:分析日志高频查询,添加高频查询最优索引
调低日志阈值,通过mtools工具分析一段时间的查询,获取到如下热点查询信息:
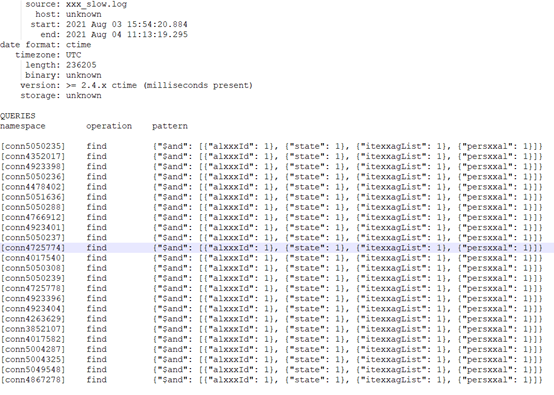
这部分高频热点查询几乎占用了99%以上的查询,因此务必确保这部分查询需要所有字段能走索引。分析该类查询对应日志,得到如下信息:
Mon Aug 2 10:47:58.015 I COMMAND [conn4352017] command xxxx.xxx command: find { find: "xxxxx", filter: { $and: [ { alxxxId:"xxxxx" }, { state: 0 }, { itemTagList: { $in: [ xxxxx ] } }, { persxxal: 0 } ] }, projection: { $sortKey: { $meta: "sortKey" } }, sort: { updateTime: 1 }, limit: 3, maxTimeMS: 10000 } planSummary: IXSCAN { alxxxId: 1.0, itexxagList: 1.0 } keysExamined:1327 docsExamined:1327 hasSortStage:1 cursorExhausted:1 keyUpdates:0 writeConflicts:0 numYields:23 nreturned:3 reslen:12036 locks:{ Global: { acquireCount: { r: 48 } }, Database: { acquireCount: { r: 24 } }, Collection: { acquireCount: { r: 24 } } } protocol:op_command 151ms 上面日志可以看出,该高频查询扫描数据行数和最终返回的数据行数差距很大,扫描了1327行,最终只获取到了3条数据,走的是 { alxxxId: 1.0, itexxagList: 1.0 }
索引,该索引不是最优索引。该高频查询是四字段的等值查询,只有两个字段走了索引,可以把该索引优化为如下索引:{ alxxxId: 1.0, itexxagList: 1.0 , persxxal:1.0, stat:1.0}
此外,从日志可以看出,该高频查询实际上还有个sort排序和limit限制,整个查询原始SQL如下:
db.xxx.find({ $and: [ { alxxxId:"xxxx" }, { state: 0 }, { itexxagList: { $in: [ xxxx ] } },{ persxxal: 0 } ] }).sort({updateTime:1}).limit(3) 该查询模型为普通多字段等值查询 + sort排序类查询 + limit限制。该类查询最优索引可能是下面两个索引中的一个:
· 索引1:普通多字段等值查询对应索引
对应查询中的如下SQL查询条件:
{ $and: [ { alxxxId:"xxx" }, { state: 0 }, { itexxagList: { $in: [ xxxx ] } }, { persxxal: 0 } ] }该SQL四个字段都为等值查询,按照散列度创建最优索引,取值越散列的字段放最左边,可以得到如下最优索引:
{ alxxxId: 1.0, itexxagList: 1.0 , persxxal:1.0, stat:1.0}如果选择该索引作为最优索引,则整个普通多字段等值查询 + sort排序类查询 + limit限制查询执行流程如下:
通过{ alxxxId: 1.0, itexxagList: 1.0 , persxxal:1.0, stat:1.0}索引找出满足{ $and: [ { alxxxId:"xxxx" }, { state: 0 }, { itexxagList: { $in: [ xxxx ] } }, { persxxal: 0 } ] }条件的所有数据。对这些满足条件的数据进行内存排序取排序好的前三条数据· 索引2:Sort排序对应最优索引
由于查询中带有limit,因此有可能直接走{updateTime:1}排序索引,通过该索引找出三条满足以下查询条件的数据:
{ $and: [ { alxxxId:"xxxx" }, { state: 0 }, { itexxagList: { $in: [ xxxx ] } },
{ persxxal: 0 } ] }整个普通多字段等值查询 + sort排序类查询 + limit限制查询对应索引选择索引1和索引2和数据分布有较大的关系,由于该查询为超高频查询,因此建议这类SQL添加2个索引,由MongoDB内核根据实际查询条件和数据分布自己决定选择那个索引作为最优索引,该高频查询对应索引如下:
{ alxxxId: 1.0, itexxagList: 1.0 , persxxal:1.0, stat:1.0}
{updateTime:1}4.7. 小结
通过前面六轮优化后,最终只保留如下8个索引:
{ "itxxxId" : 1, "alxxxId" : 1 }
{ "alxxxId" : 1, "state" : 1, "digitalxxxrmarkId" : 1, "updateTime" : 1 }
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "persxxal" : -1, "updateTime" : 1 }
{ "alxxxId" : 1, "itexxxList.photoQiniuUrl" : 1, }
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1"parentItxxxId" : 1}
{ alxxxId: 1.0, itexxagList: 1.0 , persxxal:1.0, stat:1.0}
{updateTime:1}
{ "alxxxId" : 1,"createTime" : -1}通过一系列索引优化后,最终索引减少到8个,整体收益非常明细,主要收益如下:
· 节省90% 以上CPU资源
峰值CPU消耗从之前的90%多降到优化后的10%以内
· 节省85% 左右磁盘IO资源
磁盘IO消耗从之前的60%-70%降低到10%以内
· 节省20%磁盘存储成本
由于每个索引都对应一个磁盘索引文件,索引从30个减少到8个,数据+索引最终真实磁盘消耗减少20%左右。
· 慢日志减少99%
索引优化前慢日志每秒数千条,优化后慢日志条数降低到数十条。优化由慢日志主要有求count引起,满足条件数据太多,这是正常现象。
最后,索引对MongoDB数据库查询性能起着至关重要的作用,用最少索引满足用户查询需求会极大提升数据库性能,并减少存储成本。腾讯云DBbrain for MongoDB基于SQL分类+索引规则+代价计算完美实现索引智能推荐,下期将为大家带来腾讯云索引推荐方案及实现细节的分享。
作者:腾讯云MongoDB团队
腾讯云MongoDB当前服务于游戏、电商、社交、教育、新闻资讯、金融、物联网、软件服务等多个行业;MongoDB团队(简称CMongo)致力于对开源MongoDb内核进行深度研究及持续性优化(如百万库表、物理备份、免密、审计等),为用户提供高性能、低成本、高可用性的安全数据库存储服务。后续持续分享MongoDb在腾讯内部及外部的典型应用场景、踩坑案例、性能优化、内核模块化分析。
Tags 标签
mongodb扩展阅读
Macbook m1 Big Sur 安装php7.1 mondodb 折腾记
2021-01-19 05:40:36 []MongoDB 与 Spring Boot:一个简单的 CRUD
2021-07-28 04:18:23 [Java攻城师]docker 搭一个mongodb shard cluster
2021-07-28 07:19:45 [user_IaP54NlE]TDengine在黑格智造的落地应用
2021-07-28 17:22:04 [涛思数据]Docker搭建mongodb主从结构
2021-07-28 02:53:27 [user_IaP54NlE]mongo变更数据类型
2021-07-28 15:58:25 [阿丽]Mongo 服务重启异常问题记录
2021-07-29 01:52:08 [布吉岛]node js 各类数据库常用方法封装的、心路历程、、
2021-07-28 22:36:29 [wzj5cnaz]技术分享 | 基于 mongo cluster 的 PITR 恢复案例一则
2021-07-28 21:35:16 [爱可生云数据库]2021年MongoDB中文社区北京大会
2021-07-28 17:46:57 [MongoDB中文社区]加个好友,技术交流
