MongoDB 时序新特性
王顶 -
目录:
解析 MongoDB 新特性“时序”如何在 MongoDB 中使用时序?MongoDB 时序集合性能MongoDB 时序 IOT 场景设计一、解析 MongoDB 新特性“时序”
MongoDB 时序集合是 MongoDB 5.0 新推出的功能,他能快速将段时间内的数据写入磁盘,并且提供快速时序检索的集合。与普通集合相比,时序集合在数据插入的过程中,自动将数据按照时间维度组织成最优的存储格式,也为后面应用程序对时序数据提高了查询效率。MongoDB 传统时序模式:假设我们有一个传感器每分钟测量温度并将其保存到数据库中,我们需要写入数据库中的数据流:
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [{ temperature: 10, time: 1573833152},]},
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [[ temperature: 15, time: 1573833153},]},
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [[ temperature: 14, time: 1573833154},]},
{_id: ObjectId(), deviceid: 1, date: TSODate("2019-11-10"), samples : [[ temperature: 20, time: 1573833155},]}{
_id: objectId(),
deviceid: 1,
date: ISODate ( "2019-11-10") ,
first: 1573833152,
last: 1573833155,
samples : [
{ temperature: 10, time: 1573833152},
{ temperature: 15, time : 1573833153},
{ temperature: 14, time: 1573833154),
{ temperature: 20, time : 1573833155}
]
}字段解释:
id —文档的ID,这个ID具备唯一性deviceld —查询的设备IDdate—采样日期;我们可以将其存储在此处以简化聚合first—存储桶中读取的最旧数据的时间戳last—存储桶中读取的最新数据的时间戳samples—数据容器用例中桶模式的优势:节省数据和索引的大小简化数据结构可以将需要采集的数据按照时间维度集中在一起,方便快速范围检索提升数据写入速度二、如何在 MongoDB 种使用时序
显示指定创建的集合为时序集合db.createcollection (
"weather",
{
timeseries: {
timeField: "timestamp",
metaField: "metadata",
granularity: "hours"
}
}字段含义介绍:
timeField 是时间参数,必须为 BSON data。metaField 影响维度基数,好的 metaField 应该选择低基数的,有选择性的指标,高基数必然带来性能的下降granularity 是聚合粒度(可选)参数,数据库会将一个时间段的数据聚合存放,这个参数影响性能,不影响功能expireAfterSeconds 影响数据的过期,是默认通过每60s一次的检测实现的。过期时间可配置CRUD 操作增:单条插入或批量插入集合的方式(跟传统的 collection 没有区别)删(略)改(略)查:计算时序集合时段平均值(聚合查询):
db.weather.aggregate([
{
project: {
date: {
$dateToParts: { date: "$timestamp" }
},
temp: 1
},
{
$group: {
_id: {
date: {
year : "$date. year",
month: "$date.month",
day : " $date.day"
}
avgTmp: { $avg: "stemp"}
}
])三、MongoDB 时序集合性能
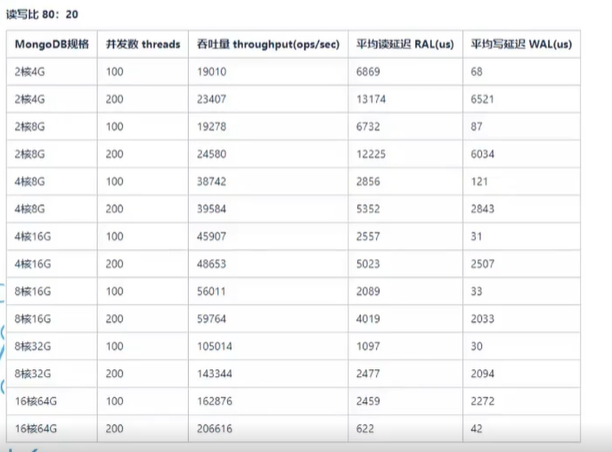
写入性能(4C 8G 128G ssd)
MongoDB 对数据的压缩支持 snappy、zstd 和 zlib 算法,在以往线上真实的数据空间大小与真实磁盘空间消耗进行对比,可以得出以下结论:
压缩算法真实数据量真实磁盘空间消耗snappy 压缩算法3.5T1-1.5Tzstd 压缩算法3.5T0.6-0.9Tzlib 压缩算法3.5T0.5-0.7THbase 默认采用的是 snappy 算法,MongoDB 时序集合默认采用 zstd 压缩算法,所以相同数据量,MongoDB 磁盘占用更低。
MongoDB时序集合使用限制:客户端加密ChangeStreamRelndex 重建索引Tiggers更新和删除限制四、MongoDB时序 IOT 场景设计
场景需求:
数据质量,实时消费 kafka 数据,并经过流式计算后,需要对数据进行展示,如流程图所示:

参考资料:
MongoDB 时间序列手册MongoDB Node.js 驱动手册 特别申明:本文内容来源网络,版权归原作者所有,如有侵权请立即与我们联系(cy198701067573@163.com),我们将及时处理。
Tags 标签
mongodb时间序列数据存储iot物联网扩展阅读
simps/mqtt:适用于 PHP 的 MQTT 协议解析和协程客户端
2020-12-15 07:18:44 []simps/mqtt v1.1.1 版本发布,支持 MQTT5 中的大部分 Property
2020-12-21 12:56:20 []simps/mqtt v1.1.2 版本发布,首个支持 MQTT v5.0 协议的 PHP library
2020-12-27 23:31:07 []PHPMQTT v1.1.4 版本发布,MQTT 协议解析 & 协程客户端
2021-01-14 21:01:58 []Macbook m1 Big Sur 安装php7.1 mondodb 折腾记
2021-01-19 05:40:36 []MongoDB 与 Spring Boot:一个简单的 CRUD
2021-07-28 04:18:23 [Java攻城师]docker 搭一个mongodb shard cluster
2021-07-28 07:19:45 [user_IaP54NlE]TDengine在黑格智造的落地应用
2021-07-28 17:22:04 [涛思数据]Docker搭建mongodb主从结构
2021-07-28 02:53:27 [user_IaP54NlE]mongo变更数据类型
2021-07-28 15:58:25 [阿丽]加个好友,技术交流
