【mongo 系列】聚合知识点梳理
阿兵云原生 -
我们先来看看是是聚合数据
数据聚合(Data Aggregation)是指合并来自不同数据源的数据。.
聚类也称聚类分析,亦称为群集分析,是对于统计数据分析的一门技术,
在许多领域受到广泛应用,包括机器学习,数据挖掘,模式识别,图像分析以及生物信息。
什么是聚合查询?聚合操作处理数据是记录并返回计算结果的
局和操作组的值来自多个文档,可以对分组数据执行各种操作以范围单个结果
聚合操作一般包含下面三类:
单一作用聚合聚合管道MapReducehttps://docs.mongodb.com/manu...

mongodb 自身提供如下几个单一作用的聚合函数,这些单一的聚合函数,相对聚合管道和mapReduce 来说不够灵活,也缺乏丰富的功能
db.集合名字.estimatedDocumentCount()粗略的计算文档的个数,是一个估计值
db.集合名字.count()计算文档的数量,是通过聚合来计算的
db.集合名字.distinct()查看某一个字段都有哪些值
例如:
> db.users.find()
{ "_id" : ObjectId("61584aeeee74dfe04dac57e9"), "name" : "xiaokeai", "age" : 25, "hobby" : "reading", "infos" : { "tall" : 175, "height" : 62 }, "school" : "cs" }
{ "_id" : ObjectId("615a56d6bc6afecd2cff8f96"), "name" : "xiaozhu", "age" : 15, "hobby" : "basketball", "infos" : { "tall" : 190, "height" : 70 }, "school" : "sh" }
{ "_id" : ObjectId("615a5856d988690b07c69f64"), "name" : "xiaopang" }
{ "_id" : ObjectId("615a5917d988690b07c69f66"), "name" : "nancy", "age" : 25, "hobby" : "study", "infos" : { "tall" : 175, "height" : 60 }, "school" : "hn" }
{ "_id" : ObjectId("615a5917d988690b07c69f67"), "name" : "job", "age" : 19, "hobby" : "basketball", "infos" : { "tall" : 170, "height" : 70 }, "school" : "nj" }
> db.users.distinct("age")
[ 15, 19, 25 ]
上述例子,使用 db.users.distinct("age") 查看 age 字段存在的 value 有哪些
https://docs.mongodb.com/manu...
聚合管道包含多个阶段,每个阶段在文件通过管道时进行转换,这里的管道,我们可以理解成 linux 里面的管道,下一个指令的输入是上一个指令的输出
db.集合名.aggregate(<pipelines>,<options>)
一组数据聚合阶段,除了 $out , $Merge,$geonear 在管道中只可以出现 1 次,其他的操作符每个阶段都可以在管道中出现多次
可选,聚合操作的其他参数
这里面包含了 查询计划,是否使用临时文件,游标,最大操作时间,读写策略,强制索引 等等
常用的管道聚合阶段梳理一下常用的管道聚合阶段如下
阶段关键字描述$match筛选条件$group分组$project显示字段$lookup多表关联$unwind展开数组$out结果汇入新表$count$文档计数$sort ,$skip,$limit排序和分页其他的阶段我们查看官网 https://docs.mongodb.com/manu...
例如 $count 的例子
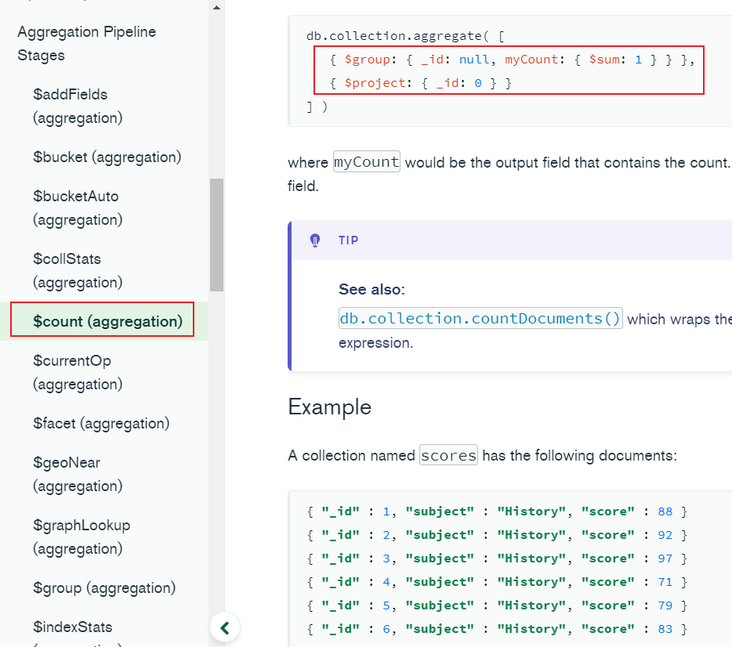
第一个 $group 就用于筛选数据,聚合管道中,此处的输出是下一个管道的输入,下一个管道是 $project 选择显示的字段
https://docs.mongodb.com/manu...
MapReduce 操作将大量的数据处理工作拆分成多个线程并行的处理,然后将结果合并在一起
MapReduce 具有如下 2 个阶段:
将具有相同 key 的文档数据整合在一起的 map 阶段组合 map 操作的结果进行统计输出的 reduce 阶段可以看一个官网的例子

emit 将 cust_id 和 amount 做成 map 映射,筛选条件是 status:"A",最后把结果放到一张新的集合中,命名为 order_totals
MapReduce 操作语法如下:
do.集合名.mapReduce(<map>,<reduce>,
{
out:<collection>,query:<document>,
sort:<document>,limit:<number>,
finalize:<function>mscope:<document>,
jsMode:<boolean>,verbose:<boolean>,
bypassDocumentValidation:<boolean>
}
)将数据拆分成键值对,交给 reduce 函数
reduce根据键将值进行统计运算
out可选,将结果汇入到指定表格中
query可选参数,筛选数据的条件,结果是送入 map
sort排序完成后,送入 map
limit限制送入 map 的文档数
finalize可选,修改 reduce 的结果后进行输出
scope可选,指定 map ,reduce ,finalize 的全局变量
jsMode可选,默认是 false, 在 mapreduce 的过程中是否将数据转换成 bson 格式
verbose可选参数,是否在结果中显示时间,默认是 false 的
bypassDocumentValidation可选参数,师傅略过数据校验的流程
聚合管道和 MapReduce 的对比比较项聚合管道MapReduce目的用于提高聚合任务的性能和可用性用于处理大数据集,数据巨大的时候,是用哪个 MapReduce 会更方便特征可以根据需要重复管道运算符,管道操作不必为每个输入文档都生成一个输出文档除分组操作外,还可执行复杂的聚合任务以及对不断增长的数据集执行增量聚合灵活性限于聚合管道支持的运算符和表达式自定义 map , reduce 以及 finalize javascript 函数提供了灵活性以及聚合逻辑输出结果返回结果作为游标,如果管道包括一个$out 或者 多个 $merge 阶段,则光标为空以各种选项 内联,新收集,合并,替换,缩小,返回结果分片支持非分片和分片输入集合支持非分片和分片输入集合再详细的对比,可以查看官网 https://docs.mongodb.com/manu...

朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
Tags 标签
mongodb扩展阅读
Macbook m1 Big Sur 安装php7.1 mondodb 折腾记
2021-01-19 05:40:36 []MongoDB 与 Spring Boot:一个简单的 CRUD
2021-07-28 04:18:23 [Java攻城师]docker 搭一个mongodb shard cluster
2021-07-28 07:19:45 [user_IaP54NlE]TDengine在黑格智造的落地应用
2021-07-28 17:22:04 [涛思数据]Docker搭建mongodb主从结构
2021-07-28 02:53:27 [user_IaP54NlE]mongo变更数据类型
2021-07-28 15:58:25 [阿丽]Mongo 服务重启异常问题记录
2021-07-29 01:52:08 [布吉岛]node js 各类数据库常用方法封装的、心路历程、、
2021-07-28 22:36:29 [wzj5cnaz]技术分享 | 基于 mongo cluster 的 PITR 恢复案例一则
2021-07-28 21:35:16 [爱可生云数据库]2021年MongoDB中文社区北京大会
2021-07-28 17:46:57 [MongoDB中文社区]加个好友,技术交流
