MySQL事务的多版本并发控制(MVCC)实现原理
白菜1031 -
参考《MySQL是怎样运行的》一、什么是多版本并发控制
多版本并发控制 技术的英文全称是 Multiversion Concurrency Control,简称 MVCC。
多版本并发控制(MVCC) 是通过保存数据在某个时间点的快照来实现并发控制的。也就是说,不管事务执行多长时间,事务内部看到的数据是不受其它事务影响的,根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
多版本并发控制 的思想就是保存数据的历史版本,通过对数据行的多个版本管理来实现数据库的并发控制。这样我们就可以通过比较版本号决定数据是否显示出来,读取数据的时候不需要加锁也可以保证事务的隔离效果。
通过 多版本并发控制 我们可以解决以下几个问题:
读写之间阻塞的问题,通过 MVCC 可以让读写互相不阻塞,即读不阻塞写,写不阻塞读,这样就可以提升事务并发处理能力。降低了死锁的概率。这是因为 MVCC 采用了乐观锁的方式,读取数据时并不需要加锁,对于写操作,也只锁定必要的行。解决一致性读的问题。一致性读也被称为快照读,当我们查询数据库在某个时间点的快照时,只能看到这个时间点之前事务提交更新的结果,而不能看到这个时间点之后事务提交的更新结果。二、版本链InnoDB存储引擎的表,每一行记录中都包含一些隐藏字段,其中下面两个字段对MySQL实现MVCC起到重要作用:
db_trx_id:最后操作(插入或更新)这条记录的事务 ID。每次一个事务对某条记录进行改动时,都会把该事务的 ID赋值给 db_trx_id 隐藏字段。db_roll_ptr:回滚指针,也就是指向这个记录的 undo 日志 信息。每次一个事务对某条引记录进行改动时,都会把旧的版本记录写入到 undo 日志 中,然后 db_roll_ptr 就相当于一个指针,可以通过它来找到该记录修改前的信息。
例如有下面一张成绩单表:
CREATE TABLE `report` (
`id` int(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL COMMENT '姓名',
`score` tinyint(3) UNSIGNED NOT NULL COMMENT '成绩',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB CHARACTER SET=utf8mb4;
INSERT INTO `report` VALUES (1, '小明', '70');表中现在只包含一条记录:
SELECT * FROM report;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 70 |
+----+--------+-------+假设插入该记录的事务 id 为20,之后有两个事务分别对这条记录进行 UPDATE 操作, 事务 id 分别为 30 和 40,操作流程如下:
事务 30事务 40BEGIN;--BEGIN;UPDATE report SET score=80 WHERE id=1;-UPDATE report SET score=81 WHERE id=1;-COMMIT;--UPDATE report SET score=90 WHERE id=1;-UPDATE report SET score=91 WHERE id=1;-COMMIT;每次对记录进行改动,都会记录一条 undo 日志,每条 undo 日志都有一个 db_roll_ptr 属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些 undo 日志都连起来,串成一条链表,如下图:

每次对记录更新后,都会将旧值放到一条 undo 日志 中,保存为该记录的一个旧版本,随着更新次数的增多,所有的版本都会被 db_roll_ptr 属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值,每个版本中还包含生成该版本时对应的事务ID(db_trx_id)。
对于使用 已提交读 和 可重复读 隔离级别的事务,必须保证读到 已经提交 的事务修改的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的。
核心问题就是:需要判断一下版本链中的哪个版本是当前事务可见的。为此,InnoDB提出了 ReadView(读视图) 的概念,这个ReadView中主要包含4个比较重要的属性:
有了 ReadView,在访问某条记录时,只需要按照如下步骤判断记录的某个版本是否可见:
如果被访问版本的 db_trx_id 值等于ReadView中的 creator_trx_id 值,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。如果被访问版本的 db_trx_id 值小于ReadView中的 min_trx_id 值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。如果被访问版本的 db_trx_id 值大于或等于ReadView中的 max_trx_id 值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。如果被访问版本的 db_trx_id 值在ReadView的 min_trx_id 和 max_trx_id 之间, db_trx_id 属性值是不是在 m_ids 列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。如果某个版本的数据对当前事务不可见,就顺着版本链找到上一个版本的数据,继续按照上边的步骤依次判断可见性,直到版本链中最早的版本。如果最早的版本也不可见,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
已提交读与可重复读隔离级别的区别在MySQL中,已提交读 和 可重复读 隔离级别的的一个非常大的区别就是它们生成 ReadView 的时机不同:
已提交读 隔离级别在每一次进行普通 SELECT 操作前都会生成一个ReadView。可重复读 只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView。已提交读:每次读取数据前都生成一个ReadView对于使用 已提交读 隔离级别的事务来说,每次读取数据前都生成一个ReadView。我们用具体的实例看一下是什么效果。
我们还是以表 report 为例,现在表 report 中只有一条记录,最后修改该条记录的事务ID为 40:
SELECT * FROM report;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 91 |
+----+--------+-------+现在系统里有两个事务id分别为50、52的事务在执行:
# 事务50
BEGIN;
UPDATE report SET score = 70 WHERE id = 1;
UPDATE report SET score = 71 WHERE id = 1;# 事务52
BEGIN;
# 更新了一些别的表的记录
...此刻,表 report 中id为1的记录得到的版本链表如下所示:

假设现在有一个使用 已提交读 隔离级别的事务开始执行:
# 将当前会话的隔离级别设为读已提交
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
SHOW VARIABLES LIKE 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | READ-COMMITTED |
+-----------------------+-----------------+# 使用读已提交隔离级别开启一个新的事务
BEGIN;
# SELECT1:事务 50、52未提交
SELECT * FROM report WHERE id = 1;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 91 |
+----+--------+-------+
# 得到的列score的值为91结合 “MVCC数据可见性算法判断流程图”,可分析出上面 SELECT1 语句的执行过程如下:
在执行SELECT语句时会先生成一个ReadView,ReadView的m_ids 列表的内容就是 [50, 52],min_trx_id 为50,max_trx_id 为53,creator_trx_id 为0。从版本链中挑选可见的记录,从图中可以看出,最新版本的列score的内容是71,该版本的 trx_id 值为 50,在 m_ids 列表内,所以不符合可见性要求,根据 db_roll_ptr 跳到上一个版本。上一个版本的列score的内容是70,该版本的 trx_id 值也为 50,也在 m_ids 列表内,所以也不符合要求,继续跳到上一个版本。上一个版本的列score的内容是91,该版本的 trx_id 值为 40,小于ReadView中的 min_trx_id 值50,所以这个版本是符合要求的,最后返回给用户的版本就是这条列score为91的记录。之后,我们把事务id为50的事务提交一下:
# 事务 50
BEGIN;
UPDATE report SET score = 70 WHERE id = 1;
UPDATE report SET score = 71 WHERE id = 1;
COMMIT;然后再到事务id为52的事务中更新一下表report中id为1的记录:
# 事务 52
BEGIN;
# 更新了一些别的表的记录
...
UPDATE report SET score = 75 WHERE id = 1;
UPDATE report SET score = 78 WHERE id = 1;此刻,表report中id为1的记录的版本链就长这样:

然后再到刚才使用 已提交读 隔离级别的事务中继续查找这条id为1的记录,如下:
# 使用读已提交隔离级别开启一个新的事务
BEGIN;
# SELECT1:事务 50、52未提交
SELECT * FROM report WHERE id = 1;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 91 |
+----+--------+-------+
# 得到的列score的值为91
# SELECT2:事务 50 提交,事务 52 未提交
SELECT * FROM report WHERE id = 1;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 71 |
+----+--------+-------+
# 得到的列score的值为71结合 “MVCC数据可见性算法流程图”,可分析出上面 SELECT2 语句的执行过程如下:
因为当前事务的隔离级别为 已提交读,所以在执行SELECT语句时会又会单独生成一个ReadView,该ReadView的m_ids 列表的内容就是 [52],min_trx_id 为52,max_trx_id 为53,creator_trx_id 为0。然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列score的内容是78,该版本的 trx_id 值为 52,在 m_ids 列表内,所以不符合可见性要求,根据 db_roll_ptr 跳到上一个版本。上一个版本的列score的内容是75,该版本的 trx_id 值为 52,也在 m_ids 列表内,所以也不符合要求,继续跳到上一个版本。上一个版本的列score的内容是71,该版本的 trx_id 值为 50,小于ReadView中的 min_trx_id 值52。所以这个版本是符合要求的,最后返回给用户的版本就是这条列score为71的记录。以此类推,如果之后事务id为52的记录也提交了,再次在使用已提交读隔离级别的事务中查询 SELECT * FROM report WHERE id = 1; 时,得到的结果就是列score的值为78了,具体流程不再分析。
总结一下就是:使用读已提交隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。
对于使用 可重复读 隔离级别的事务来说,只会在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。我们还是用具体的实例看一下是什么效果。
我们还是以表 report 为例,现在表 report 中只有一条记录,最后修改该条记录的事务ID为 52:
SELECT * FROM report;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 78 |
+----+--------+-------+现在系统里有两个事务id分别为60、62的事务在执行:
# 事务 60
BEGIN;
UPDATE report SET score = 60 WHERE id = 1;
UPDATE report SET score = 61 WHERE id = 1;# 事务 62
BEGIN;
# 更新了一些别的表的记录
...此刻,表 report 中id为1的记录得到的版本链表如下所示:

假设现在有一个使用 可重复读 隔离级别的事务开始执行:
# 将当前会话的隔离级别设为读已提交
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SHOW VARIABLES LIKE 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+# 使用可重复读隔离级别开启一个新的事务
BEGIN;
# SELECT1:事务 60、62未提交
SELECT * FROM report WHERE id = 1;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 78 |
+----+--------+-------+
# 得到的列score的值为78结合 “MVCC数据可见性算法判断流程图”,可分析出上面 SELECT1 语句的执行过程如下:
在执行SELECT语句时会先生成一个ReadView,ReadView的m_ids 列表的内容就是 [60, 62],min_trx_id 为60,max_trx_id 为63,creator_trx_id 为0。从版本链中挑选可见的记录,从图中可以看出,最新版本的列score的内容是61,该版本的 trx_id 值为 60,在 m_ids 列表内,所以不符合可见性要求,根据 db_roll_ptr 跳到上一个版本。上一个版本的列score的内容是60,该版本的 trx_id 值也为 60,也在 m_ids 列表内,所以也不符合要求,继续跳到上一个版本。上一个版本的列score的内容是78,该版本的 trx_id 值为 52,小于ReadView中的 min_trx_id 值60,所以这个版本是符合要求的,最后返回给用户的版本就是这条列score为78的记录。之后,我们把事务id为60的事务提交一下,就像这样:
# 事务 60
BEGIN;
UPDATE report SET score = 60 WHERE id = 1;
UPDATE report SET score = 61 WHERE id = 1;
COMMIT;然后再到事务id为62的事务中更新一下表report中id为1的记录:
# 事务 62
BEGIN;
# 更新了一些别的表的记录
...
UPDATE report SET score = 65 WHERE id = 1;
UPDATE report SET score = 68 WHERE id = 1;此刻,表report中id为1的记录的版本链就长这样:
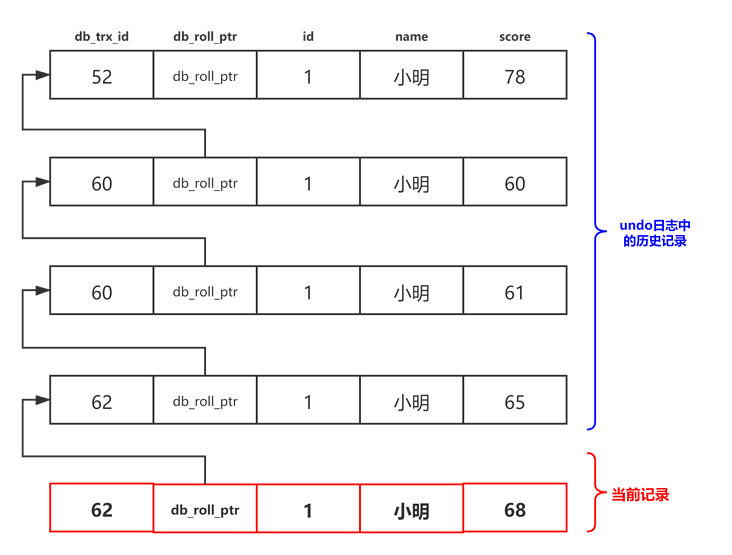
然后再到刚才使用 可重复读 隔离级别开启的事务中继续查找这个id为1的记录,如下:
# 使用可重复读隔离级别开启一个新的事务
BEGIN;
# SELECT1:事务 60、62未提交
SELECT * FROM report WHERE id = 1;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 78 |
+----+--------+-------+
# 得到的列score的值为78
# SELECT2:事务 60 提交,事务 62 未提交
SELECT * FROM report WHERE id = 1;
+----+--------+-------+
| id | name | score |
+----+--------+-------+
| 1 | 小明 | 78 |
+----+--------+-------+
# 得到的列score的值仍为78上面 SELECT2 语句的执行过程如下:
因为当前事务的隔离级别为 可重复读,而之前在执行SELECT1 时已经生成过ReadView了,所以此时直接复用之前的ReadView,之前的ReadView的m_ids 列表的内容就是 [60, 62],min_trx_id 为60,max_trx_id 为63,creator_trx_id 为0。然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列score的内容是68,该版本的 trx_id 值为 62,在 m_ids 列表内,所以不符合可见性要求,根据 db_roll_ptr 跳到上一个版本。上一个版本的列score的内容是65,该版本的 trx_id 值为 62,也在 m_ids 列表内,所以也不符合要求,继续跳到上一个版本。上一个版本的列score的内容是61,该版本的 trx_id 值为 60,而 m_ids 列表中是包含值为 60 的事务id的,所以该版本也不符合要求,同理下一个列score的内容是60的版本也不符合要求。继续跳到上一个版本。上一个版本的列score的内容是78,该版本的 trx_id 值为52,小于ReadView中的 min_trx_id 值60,所以这个版本是符合要求的,最后返回给用户的版本就是这条列score为78的记录。也就是说两次SELECT查询得到的结果是重复的,记录score的值都是78,这就是可重复读的意义。如果我们之后再把事务id为62的记录提交了,然后再使用 可重复读 隔离级别的事务继续查找这个id为1的记录,得到的结果还是score为78。
php介绍
PHP即“超文本预处理器”,是一种通用开源脚本语言。PHP是在服务器端执行的脚本语言,与C语言类似,是常用的网站编程语言。PHP独特的语法混合了C、Java、Perl以及 PHP 自创的语法。利于学习,使用广泛,主要适用于Web开发领域。
Tags 标签
phpjavapythonmysql数据库扩展阅读
隐藏apache版本信息
2018-09-30 10:56:15 []CentOS 6.5安装php5.6
2018-09-30 11:36:53 []mysql命令行常用命令
2020-06-28 19:17:05 []PHP版ZIP压缩解压类库
2018-12-22 13:11:00 []阿里云CentOS-7.2安装mysql
2019-04-23 23:00:14 []CentOS7.2安装 PHP7.3.4 操作详细教程
2020-06-28 19:09:43 []PHP 设置脚本超时时间、PHP脚本内存限制设置
2020-06-28 19:09:43 []PHP 函数filesize获取文件大小错误,一直不变
2020-06-28 19:09:43 []Linux php: command not found
2020-02-05 01:30:13 []php 缓冲区 buffer 原理
2020-06-28 19:09:43 []加个好友,技术交流
