Python轻松抓取微信公众号文章
小徐 -
今天继续向 Python 头条添加数据信息,完成了微信公号的爬虫,接下来会继续通过搜狗的知乎搜索抓取知乎上与 Python 相关的文章、问答。微信公众号的文章链接有些是具有时效性的,过一段时间会变成参数错误而无法访问,但是我们发现从公众号后台点击过去得到的链接却是永久链接,其参数不会改变链接也不会失效,也就是说只要能够获得这些参数就可以得到永久链接。通过观察发现即使从搜狗搜索入口的有时效性的链接访问网页,其源码中也带有这些参数: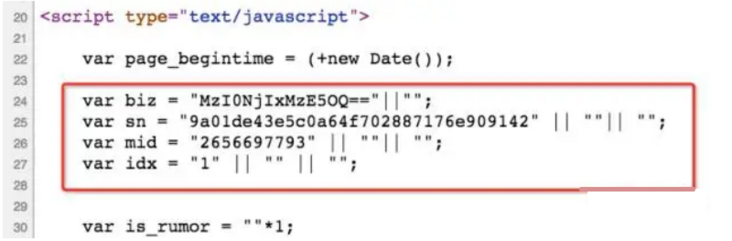
所以只要解析这几个参数,就可以构造出永久链接。
首先通过搜狗搜索入口,可以获取 Python 关键词搜索的结果,地址为:
HOST = 'http://weixin.sogou.com/'
entry = HOST + "weixin?type=2&query=Python&page={}"提取链接、标题和摘要信息:
import requests as req
import re
rInfo = r'<h4[\s\S]*?href="([\s\S]*?)".*?>([\s\S]*?)<\/a>[\s\S]*?<\/h4>\s*<p[\s\S]*?>([\s\S]*?)<\/p>'
html = req.get(entry.format(1)) # 第一页
infos = re.findall(rInfo, html)由于关键词搜索会在标题或摘要中产生特定格式的标签,需要过滤:
def remove_tags(s):
return re.sub(r'<.*?>', '', s)然后根据时效性链接获取文章内容,并从中提取参数信息:
from html import unescape
from urllib.parse import urlencode
def weixin_params(link):
html = req.get(link)
rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");'
params = re.findall(rParams, html)
if len(params) == 0:
return None
return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]}
for (link, title, abstract) in infos:
title = unescape(self.remove_tag(title))
abstract = unescape(self.remove_tag(abstract))
params = weixin_params(link)
if params is not None:
link = "http://mp.weixin.qq.com/s?" + urlencode(params)
print(link, title, abstract)看到文章最后,如果觉得此篇文章对您有帮助的话,麻烦点个赞再走哦~谢谢阅读~
特别申明:本文内容来源网络,版权归原作者所有,如有侵权请立即与我们联系(cy198701067573@163.com),我们将及时处理。
php介绍
PHP即“超文本预处理器”,是一种通用开源脚本语言。PHP是在服务器端执行的脚本语言,与C语言类似,是常用的网站编程语言。PHP独特的语法混合了C、Java、Perl以及 PHP 自创的语法。利于学习,使用广泛,主要适用于Web开发领域。
上一篇: 学习Python后,有什么项目可以练手?
下一篇: b2b商城系统开发如何做?
Tags 标签
php扩展阅读
隐藏apache版本信息
2018-09-30 10:56:15 []CentOS 6.5安装php5.6
2018-09-30 11:36:53 []PHP版ZIP压缩解压类库
2018-12-22 13:11:00 []CentOS7.2安装 PHP7.3.4 操作详细教程
2020-06-28 19:09:43 []PHP 设置脚本超时时间、PHP脚本内存限制设置
2020-06-28 19:09:43 []PHP 函数filesize获取文件大小错误,一直不变
2020-06-28 19:09:43 []Linux php: command not found
2020-02-05 01:30:13 []php 缓冲区 buffer 原理
2020-06-28 19:09:43 []PHP中三种设置脚本最大执行时间的方法
2020-06-28 19:17:34 []加个好友,技术交流
